
Das Wichtigste in Kürze:
- Earned Media dominiert: KI-Suchmaschinen zitieren vor allem redaktionelle Drittquellen wie Fachartikel, Blogs und Pressebeiträge – deutlich häufiger als Firmen-Websites.
- Autorität & Struktur zählen: Inhalte mit hoher Domain Authority, klarer Gliederung, ausreichender Tiefe und eindeutiger Sprache haben die besten Chancen, von KI-Modellen aufgegriffen zu werde.
- Kontext ist entscheidend: Welche Quelle zitiert wird, hängt stark von der Suchintention und der Phase der Customer Journey ab – von Überblicksartikeln bis hin zu Produktspezifikationen.
- Technische Zugänglichkeit nicht vergessen: Nur Inhalte, die für LLM-Crawler sauber erreichbar und gut interpretierbar sind (HTML, Struktur, Ladezeit), schaffen es in die Antwortsysteme.
Du hast hart daran gearbeitet, hochwertigen Content zu erstellen – aber wenn Nutzer KI-Suchsysteme wie ChatGPT oder Perplexity befragen, tauchst du trotzdem nicht auf?
Die Regeln haben sich geändert:
Statt wie früher primär auf technische SEO-Signale und Backlinks zu schauen, entscheiden KI-Modelle nach ganz anderen Kriterien, welche Inhalte sie zitieren – und welche nicht.
Sichtbarkeit in Chatbots, AI Overviews und anderen generativen Suchoberflächen erfordert ein Umdenken:
Es geht um Vertrauen, Kontext, Verständlichkeit und Relevanz.
In diesem Ratgeber lernst du, welche Arten von Inhalten aktuell besonders häufig zitiert werden, warum gerade diese Formate bevorzugt werden – und was du daraus konkret für deine Content-Strategie ableiten kannst.
-
 Zuletzt aktualisiert: 6. November 2025KI-Suchmaschinen 2025: KI-Suche verstehen & vergleichen
Zuletzt aktualisiert: 6. November 2025KI-Suchmaschinen 2025: KI-Suche verstehen & vergleichen -
 Zuletzt aktualisiert: 20. November 2025Marketing-KPIs für KI-Suche (LLMO/GEO/AEO)
Zuletzt aktualisiert: 20. November 2025Marketing-KPIs für KI-Suche (LLMO/GEO/AEO) -
Zuletzt aktualisiert: 20. Mai 2025Content-Strategien für KI-Suchmaschinen
-
 Zuletzt aktualisiert: 11. Januar 2026Google AI Overviews: Was sich 2025 für SEO & SEA ändert
Zuletzt aktualisiert: 11. Januar 2026Google AI Overviews: Was sich 2025 für SEO & SEA ändert -
 Zuletzt aktualisiert: 11. Januar 2026ChatGPT Search (SearchGPT) Optimierung: Die Anleitung
Zuletzt aktualisiert: 11. Januar 2026ChatGPT Search (SearchGPT) Optimierung: Die Anleitung
Video
Diesen Ratgeber gibt es auch als Video:
Welche Arten von Inhalten zitieren KI-Suchmaschinen derzeit bevorzugt?
Aktuelle Studien und Audits liefern hierzu interessante Befunde. Analysen von über 250.000 Quellen in KI-Antworten zeigen, dass der mit Abstand größte Anteil auf Earned Media – also Drittseiten wie redaktionelle Artikel, Fachblogs oder Affiliate-Websites – entfällt .
Mit anderen Worten:
KI-Systeme zitieren sehr häufig Inhalte, die nicht von der suchenden Person selbst (oder deren Firma) stammen, sondern unabhängige Informationsquellen. Im Schnitt bestehen KI-Antworten zu rund 70–80 % aus Verweisen auf externe Ratgeberseiten, Presseartikel, Review-Portale oder Blogs.
Ein kleinerer Prozentsatz entfällt auf User Generated Content (UGC) wie Forenbeiträge, Community-Fragen (z.B. Reddit) oder Bewertungen, und ein weiterer kleiner Anteil auf Owned Media – das heißt direkte Quellen von Hersteller-Websites oder Unternehmensblogs.
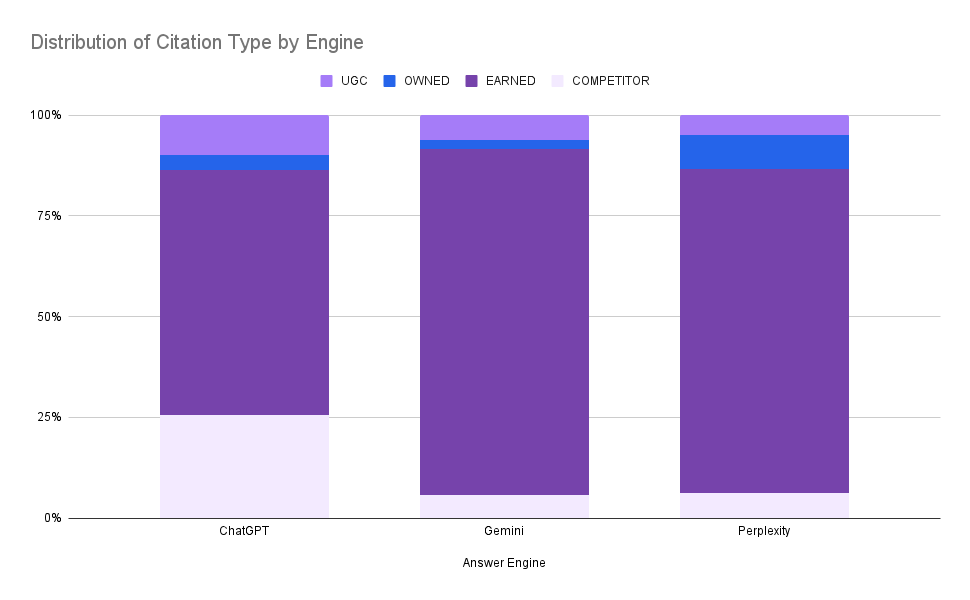
Warum werden diese Inhalte zitiert?
Mehrere Gründe lassen sich herausarbeiten:
Autorität & Reputation
KI-Modelle bevorzugen Quellen, die sie als vertrauenswürdig einstufen. Oft sind das etablierte Medien (News-Seiten, große Magazine) und bekannte Fachportale.
So wurde in einer Analyse von Kevin Indig festgestellt, dass Bing Copilot und Perplexity überproportional häufig Nachrichtenmedien und Unternehmenswebsites als Quellen anführen.
Auch ein starker Domain-Authority-Score hilft laut einer Studie von XFunnel – rund 31,5 % der zitierten Quellen hatten sehr hohe Domain Authority (80–100), weitere ca. 41,6 % lagen im mittleren Bereich (20–79) und nur <5 % waren Low-Authority-Seiten. Das heißt, hochwertige Seiten werden bevorzugt.
Dennoch:
Interessanterweise tauchen auch viele „Mid-Tier“-Quellen (mittlere DA, spezialisierte Blogs) regelmäßig auf – offenbar, weil sie Inhalte bereitstellen, die Top-Seiten so nicht anbieten. Extrem schwache oder unseriöse Domains (DA <20) werden dagegen selten zitiert (nur ~5 % der Fälle), was zeigt, dass eine gewisse Grundautorität nötig ist, um im KI-Kontext aufzutauchen.
Inhaltliche Tiefe & Relevanz
KI-Suchergebnisse belohnen umfangreiche, gut strukturierte Inhalte, die eine Frage umfassend beantworten.
Eine Untersuchung von 7.000 KI-Zitaten fand, dass die meistzitierten Inhalte signifikant längere Texte und mehr Unterabschnitte hatten als der Durchschnitt. Wort- und Satzanzahl erwiesen sich als stärkste Unterscheidungsmerkmale bei Top-10%-Inhalten.
Der Grund:
Längere Artikel decken mehr Facetten ab und haben dadurch eine höhere Chance, genau den Ausschnitt zu enthalten, den eine spezifische Nutzerfrage erfordert.
Unsere Empfehlung ist es trotzdem, informative Inhalte nicht noch länger zu machen, sondern besser auf Seiten passend zu unterschiedlichen Suchintentionen aufzuteilen.
In dieser Folge erkläre ich dir, worauf es dabei ankommt:
Struktur spielt dabei ebenfalls eine Rolle:
Inhalte, die klar gegliedert sind (mit Überschriften, Abschnitten, Listen), lassen sich leichter an den richtigen Stellen auslesen.
KI-Modelle können dann z.B. genau den Abschnitt „Vor- und Nachteile“ oder „Schritt-für-Schritt Anleitung“ als Antwortbaustein heranziehen. Primärquellen mit konkreten Daten oder Definitionen – etwa Wikipedia-ähnliche Sektionen – sind besonders wertvoll, da sie direkt zitierfähiges Wissen liefern.
Klarheit & Verständlichkeit
Je präziser und verständlicher ein Text formuliert ist, desto eher kann ihn die KI sinnvoll übernehmen.
Modelle analysieren die Lesbarkeit (Flesch-Index) und bevorzugen mittlere Werte – zu komplizierte Fachsprache birgt Fehlinterpretationsrisiken, zu einfache Sprache passt evtl. nicht zum gewünschten Ton. In der genannten Studie wog ChatGPT z.B. den Flesch-Wert eines Textes als einen Faktor bei der Quellenauswahl mit.
Ein gut erklärter Satz wie „XYZ ist ein Framework, das 2020 von ABC entwickelt wurde und der Optimierung von KI-Modellen dient“ hat bessere Chancen zitiert zu werden als ein unklarer oder umständlicher Absatz.
Klarheit erhöht auch die Verlässlichkeit:
Die KI läuft weniger Gefahr, Inhalte falsch zu kontextualisieren, wenn die Quelle eindeutig ist. Daher werden Quellen mit sauberer Faktendarstellung und geringer Mehrdeutigkeit bevorzugt.
Einzigartigkeit & Datenbasis
Häufig zitiert werden Inhalte, die exklusives Wissen oder aktuelle Daten liefern.
KI-Modelle möchten dem Nutzer Mehrwert bieten und greifen daher gerne auf Originalstudien, Statistiken, Testberichte oder Fallstudien zurück.
Ich weise ja gerne meinen Videos darauf hin, dass Industrie-Reports mit exklusiven Daten, eigene Umfragen, Case Studies oder Thought-Leadership-Artikel von ausgewiesenen Experten essentiell für Sichtbarkeit in Generative Engines sind.
Wie du sonst noch für einzigartige Informationen sorgen kannst, lernst du in diesem Video:
https://www.youtube.com/watch?v=xDwzv3Vs3ZI
Solche Inhalte fungieren als Primärquelle, auf die auch andere Seiten verweisen – was ihre Glaubwürdigkeit weiter steigert. Beispielsweise würde eine KI bei der Frage nach Marktanteilen einer Technologie vorzugsweise den originalen Bericht einer Marktforschungsfirma zitieren, anstatt einen Blog, der sekundär darüber berichtet. Unternehmen, die eigene Zahlen oder Erkenntnisse publizieren, können so zum Ursprung von Antworten werden.
Dazu aber noch eine Notiz:
Aktuell werden in generativen Engines extrem oft Übersichten mit Statistiken zitiert. Der Grund dafür ist, dass die primäre Quelle online nicht mehr auffindbar oder nicht verfügbar ist.
Stadium der Kundenreise und Absicht
Die Art der zitierten Inhalte variiert mit der Nutzerintention bzw. Phase der Customer Journey.
In frühen Phasen (Problem-Erkennung, Information) dominieren redaktionelle Drittquellen und Ratgeber – Nutzer wollen einen breiten Überblick, den z.B. Presseartikel oder neutrale Blogs bieten.
In der Vergleichsphase (Mid-Funnel) steigt der Anteil an UGC erheblich, etwa durch Erfahrungen auf Foren, Produktbewertungen oder Peer-Reviews, da echte Erfahrungsberichte gefragt sind.
Gegen Ende der Kundenreise (Produktentscheidung, Kauf) ziehen KI-Antworten dann vermehrt offizielle Quellen heran – Herstellerseiten – weil detaillierte Spezifikationen oder Preise benötigt werden.
Das bedeutet:
Welcher Content zitiert wird, hängt auch vom Kontext der Frage ab. Ein und dasselbe KI-System könnte bei einer allgemeinen Frage („Wie funktioniert X?“) einen Wikipedia-ähnlichen Blog zitieren, bei einer spezifischen Produktfrage („Preis und Funktionen von Produkt Y“) aber direkt die Herstellerseite Y nennen.
Für Content-Strategen heißt das, man sollte sowohl breit gefächerte Info-Inhalte abdecken als auch spezifische Detailseiten bereitstellen, je nachdem, wo man im Funnel auftauchen möchte.
Technische Zugänglichkeit
Seiten, die für Crawler schwer zugänglich sind – z.B. weil wesentliche Inhalte nur via JavaScript nachgeladen werden oder hinter Login/Paywall liegen – werden von KI-Suchmaschinen tendenziell gemieden.
LLM-Crawler sind oftmals weniger geduldig als Googlebot, was komplexe Client-seitige Renderings angeht.
Einfaches, sauberes HTML und schnelle Server-Antworten erhöhen die Chance, dass eine KI Ihre Inhalte überhaupt „sieht“ und indexiert.
Eine korrekt gepflegte Sitemap, aussagekräftige Meta-Daten und semantisches Markup können ebenfalls hilfreich sein, damit KI-Systeme Ihre Seiteninhalte richtig einordnen.
Technische Probleme dagegen (z.B. fehlende Mobiloptimierung, langsame Ladezeiten) wirken indirekt – sie können dazu führen, dass die Seite im Web weniger verbreitet/zitiert wird und somit auch der KI weniger auffällt.
Was das für deine Content-Strategie bedeutet
Zusammenfassend zitiert die aktuelle Generation von KI-Suchmaschinen bevorzugt inhaltlich reichhaltige, klar formulierte und glaubwürdige Inhalte. Sowohl große Nachrichtenportale als auch spezialisierte Blogs finden sich in den Quellen wieder – entscheidend ist, dass sie für die gestellte Frage die beste verfügbare Antwort liefern.
Wer mit seinem Content Autorität aufbaut, Mehrwert bietet und gleichzeitig crawler-freundlich bleibt, hat gute Chancen, von ChatGPT, Perplexity, AI Overviews und Co. als Referenz herangezogen zu werden.
Wenn du sicherstellen willst, dass eure Inhalte in ChatGPT, Perplexity & Co. auftauchen – nicht nur in klassischen Suchergebnissen –, dann unterstützen wir dich gerne.
Ob Content-Audit, Strategieentwicklung oder der Aufbau KI-relevanter Autorität:
Gemeinsam machen wir eure Website zur vertrauenswürdigen Quelle für die Suchsysteme von morgen. Melde dich jetzt für ein unverbindliches Beratungsgespräch






Kommentieren