
Er stört vor allem die Suchmaschine und hat das Potential, User*innen gewaltig zu verwirren. Aus SEO-Sicht und teils aus rechtlichen Gründen ist er deshalb nicht empfehlenswert. Die Rede ist von sogenanntem Duplicate Content, also doppelten Inhalten, die du wirklich so gar nicht brauchen kannst.
Lies weiter, wenn du unter anderem wissen willst, warum Google Duplicate Content so sehr verabscheut (Spoiler Alert: weil Google User Experience großschreibt und keine Ressourcen verschwenden will), wie du doppelte Inhalte findest und wie du sie in Zukunft vermeiden kannst.
„The Lowest rating is appropriate if all or almost all of the MC [Main Content] on the page is copied with little or no time, effort, expertise, manual curation, or added value for users. Such pages should be rated Lowest, even if the page assigns credit for the content to another source.“
— Google in den Search Quality Evaluator Guidelines
Das ist die Aufforderung, die Google für seine Search Quality Evaluators bereithält. Du siehst: Die Suchmaschine hält nicht allzu viel von duplizierten Inhalten. Schon gar nicht, wenn sie von anderen Seiten zusammengetragen – oder geklaut – sind.
Was ist Duplicate Content?
Duplicate Content (DC) ist, kurz gesagt, das Vorhandensein exakt identischer Inhalte bzw. sehr ähnlicher Inhalte auf einer einzigen Domain. Auch ein Inhalt, der auf mehreren Webseiten so oder so ähnlich anzutreffen ist, gilt als Duplicate Content.
In der Theorie ist es also ganz einfach: Der Begriff meint zwei Inhalte, die zweimal im Internet unter unterschiedlichen URLs zu finden sind und sich entweder entsprechen oder auffällige Ähnlichkeiten aufweisen.
In der Praxis ist die Unterscheidung aber gar nicht immer so einfach. Ja, es kann vorkommen, dass umfangreiche Textblöcke 1:1 kopiert wurden und sich ein Konkurrent ganz frech deiner einzigartigen Inhalte angenommen hat.
Genauso gut kann es allerdings sein, dass deine Inhalte über mehrere Domains, Subdomains oder URLs erreichbar sind. Auch das ist Duplicate Content, den du erst einmal aufspüren und eliminieren musst.
Duplicate Content, der auf anderen Webseiten aufzufinden ist, wird als externer Duplicate Content bezeichnet. Alles, was sich innerhalb der eigenen Reihen befindet, ist hingegen interner Duplicate Content.
Wodurch entsteht doppelter Content meistens?
- mit und ohne www möglich
- HTTP und HTTPS möglich
- Trailing Slash
- Facettensuche oder Facettennavigation (Parameter)
- Sitzungs-IDs (Parameter)
- überschneidende Schlagworte
- Paginierung
- alternative Versionen, wie z. B. Druckseiten oder AMP
- Entwicklungsumgebungen
- schlecht umgesetzte Mehrsprachigkeit
- Scraper
Ab welchem Prozentsatz handelt es sich für Google um Double Content?
Black-Hat-SEO-Quellen behaupten, eine URL gilt für Google als Duplicate Content, wenn diese mindestens 70 Prozent des Inhalts mit einem anderen Artikel oder einer anderen Seite teilt. Hierbei ist jedoch der Kontext wichtig.
Gemeint sind nicht die Inhalte auf deiner Website, sondern Content für Linkaufbau.
Da Black Hat SEOs Linkbuilding auf großer Skala mit mehreren Tiers betreiben, benötigen sie eine gigantische Menge an Inhalten. Sie nutzen dafür Text-Spinning. Ein Duplicate-Content-Prozentsatz von unter 70 Prozent sorgt ihrer Meinung nach dafür, dass die URL noch von Google indexiert und so der Backlink von dieser URL gezählt wird.
Die Inhalte auf deiner Website sollten immer einzigartig sein (Ausnahme: Zitate und Ähnliches).
Interner Duplicate Content
Interner Duplicate Content befindet sich innerhalb deiner eigenen Domain und tritt besonders gehäuft bei bestimmten Arten von Webseiten auf. Besonders anfällig für Duplicate Content sind Online-Shops mit Shopsystemen und Redaktions-CMS. Natürlich bedeutet das nicht, dass du mit einem anderen CMS nicht ebenfalls in die Duplicate-Content-Falle tappen kannst.
Schnell passiert ist Duplicate Content, wenn du eine Version deiner Webseite anbietest, die unabhängig von deiner Desktop-Version und nur auf Mobiltelefone angepasst ist. Sogar druckerfreundliche Seiten können schon als doppelter Inhalt gewertet werden.
Auf Seitenebene sind es vor allem diese Seitentypen, die unter Umständen betroffen sein könnten. Es schadet also nie, dementsprechend mal aufzuräumen:
- Seitentypen, über die nur bestimmte Inhalte angezeigt werden, d. h. Tag-Seiten, Filter-Seiten, interne Suchergebnislisten
- Kategorienseiten
- Produkteinzelseiten, die in unterschiedliche Kategorien eingeordnet werden können und immer eine eigene URL zugewiesen bekommen (deswegen dürfen Produktseiten niemals die Kategorie in der URL haben)
- Beiträge und Inhalte in unterschiedlichen Kategorien (wenn sie die Kategorie in der URL haben)
- Paginierung vs. Komplettansicht, wenn nicht alle paginierten Seiten auf die Komplettansicht verweisen
Das sind also die Seiten, die du im Blick behalten musst. Entdeckst du hier Duplicate Content, solltest du daran etwas ändern, selbst wenn das zugegebenermaßen relativ aufwendig sein kann (kann, nicht muss).
Aber Achtung, nicht nur an offensichtlichen Stellen gibt es Duplicate Content.
Doppelte Inhalte können sich extrem gut verstecken. Das gilt vor allem für Informationen in den Seitenleisten und im Footer, auch Boilerplate Content genannt. Schließlich werden hier einige wichtige Informationen zu deinem Unternehmen angezeigt – und das auf jeder einzelnen URL. Lange Inhalte solltest du hier vermeiden, am besten beschränkst du dich auf kurze, knappe Informationen.

Wiederkehrende Textblöcke sorgen für „Noise“ (ja, so nennt man das in Black Hat Kreisen). Damit ist gemeint, dass die Relevanz und Qualität der jeweiligen Seite reduziert wird. Deshalb solltest du wiederholende Textfragmente tunlichst vermeiden.
Wenn du deine Produkte für unterschiedliche Länder zur Verfügung stellst, musst du ebenfalls ein wenig aufpassen.
Während Übersetzungen richtig gekennzeichnet kein Problem darstellen, denkt man normalerweise für deutsche/österreichische/schweizerdeutsche Versionen nicht unbedingt an eine Kennzeichnung mit „hreflang.“ Das sollte man aber, um Duplicate Content ausschließen zu können.
Nicht zuletzt bei einem Relaunch sollte auf Duplicate Content ein besonderes Augenmerk gerichtet werden. Ein häufiger Fehler ist nämlich, dass die Testdomain für Außenstehende schon einzusehen und damit auch für den Googlebot zugänglich ist. Ein Passwort über die „.htaccess“ ist deshalb eine wichtige Grundvoraussetzung, um sorgenfrei am Relaunch arbeiten zu können.
Externer Duplicate Content
Interner Duplicate Content ist nicht gerade ideal, ein größeres Problem stellt aber externer Duplicate Content dar. So wird Duplicate Content bezeichnet, der über zwei oder mehrere Domains hinweg besteht. Nicht immer sind fiese Copy-and-Paster schuld daran, obwohl Content-Diebstahl und Content-Scraping bzw. kopierte Inhalte natürlich einen gewissen Anteil am externen Duplicate Content haben.
Scraper-Seiten kopieren deinen Content automatisch. Diesen Content monetarisieren sie dann mit Werbung. Grundsätzlich ist das kein Problem. Wenn du eine sehr kleine und von der Domainautorität schwache Website hast, solltest du neue Inhalte aber immer gleich durch „Abruf wie durch Google“ indizieren lassen.

Doch auch externer Duplicate Content kann hausgemacht sein. So zum Beispiel, wenn deine Webseite nicht nur unter einem Domainnamen, sondern gleich über mehrere Domains erreichbar ist. In diesem Fall stellst du dir selbst ein Bein, denn Google weiß nicht mehr, was wirklich relevant ist. Ranking-Probleme sind die Folge.
Weitere Quellen externer doppelter Inhalte, die für Wirbel im Ranking sorgen können, sind beispielsweise immer dann zu finden, wenn:
- du die Artikelbeschreibungen einfach von der Herstellerseite übernimmst.
- Inhalte über einen RSS-Feed eingespielt werden.
- Pressemeldungen weiter verbreitet werden.
Near Duplicate Content
Es steckt schon im Namen: Near Duplicate Content sind doppelte Inhalte, aber eben nicht ganz.
Laut Google gibt es zwei mögliche Szenarien, ab wann Inhalt als Near Duplicate Content eingestuft wird:
- Der Inhalt wurde kopiert, aber dabei leicht abgeändert.
- Es handelt sich um eine 1:1-Kopie, aber der Boilerplate Content ist anders.
Googles Gary Illyes sorgt dafür, dass man ein wenig mehr versteht, wie Google die Duplicate-Content-Welt sieht:
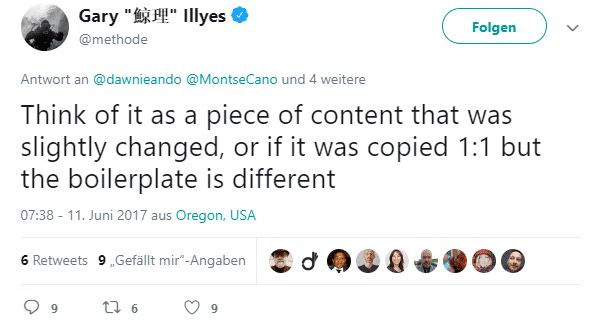
Ist alles doppelter Content, was so aussieht?
Nicht alles, was doppelt auftritt, ist Duplicate Content. Und nicht alles, was Duplicate Content ist, macht wirklich Probleme. Keine Sorgen musst du dir bei diesen Elementen machen:
- Übersetzungen – immer vorausgesetzt, du hast sie durch „hreflang“ richtig gekennzeichnet
- zitierte Inhalte – sofern sie im Quelltext richtig gekennzeichnet sind
- Content in Apps
Dieses Beispiel von Sistrix zeigt: Nur, weil du Übersetzungen auf deiner Seite hast, heißt das noch lange nicht, dass du doppelten Content am laufenden Meter produzierst.

Wenn Google an dieser Stelle die richtigen Hinweise erhält, musst du dir hier nicht den Kopf zerbrechen und keine Angst davor haben, dass du im Suchmaschinen-Nirvana verschwindest.
Duplicate Content hat also einigermaßen viele Gesichter. Vielleicht sagt Gary Illyes u. a. deshalb, dass es keine pauschale Antwort auf die Frage gibt, was duplizierte Inhalte eigentlich sind.
Was Google gegen Duplicate Content hat
Dass die Suchmaschine eine Art Feldzug gegen Duplicate Content angetreten hat, zeigen unzählige Veröffentlichungen zum Thema doppelte Inhalte im Internet. Übrigens geht Google laut eigenen Aussagen nicht automatisch davon aus, dass hinter jedem identischen Textschnippselchen böse Absicht steckt.
Aber das ist nicht Googles Hauptproblem. Das Unternehmen selbst sagt:
„Google ist sehr darum bemüht, Seiten mit unterschiedlichen Informationen zu indizieren und anzuzeigen […].“
Das Crawlen und Indexieren von Seiten kostet Ressourcen. Google will diese Prozesse natürlich so effizient wie möglich gestalten, um die Kosten zu reduzieren. Und das ist nicht einfach, bei den unvorstellbaren Mengen an Content, die publiziert werden…
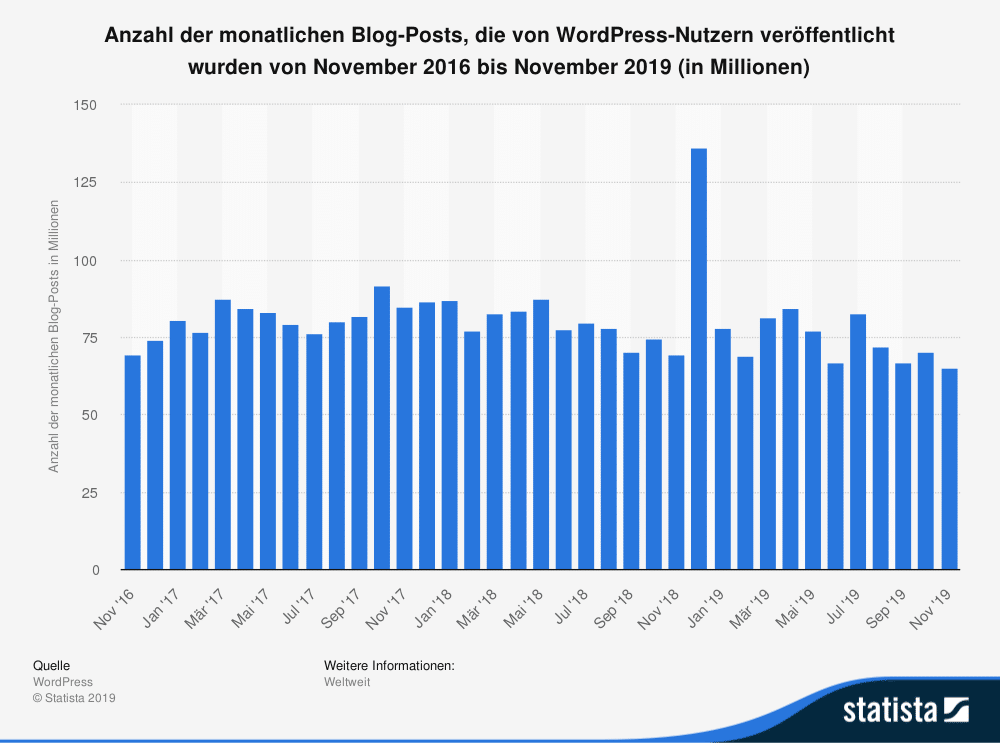
Insgesamt rund 65,02 Millionen Blog-Posts wurden zum Beispiel von WordPress-Nutzer*innen im November 2019 veröffentlicht. Gegenüber dem Vormonat entspricht dies einer Abnahme um mehr als fünf Millionen Veröffentlichungen.
Zudem wird durch doppelten Content die URL-Bewertung pro Suchanfrage erschwert. Für den Googlebot ist es eine Herausforderung, das Original zu bestimmen und diesem die passenden Signale zuzuordnen.
Und auch für internen Duplicate Content ist Eindeutigkeit ein wichtiges Gebot. Ansonsten drohen nämlich verschiedene Seiten innerhalb deiner Domain in einen Konkurrenzkampf um ein und dasselbe Keyword zu treten.
Man spricht dann von Keyword-Kannibalisierung. Normalerweise meint dieser Begriff, dass mehrere Seiten auf das gleiche Fokus-Keyword optimiert sind. Den gleichen Effekt erzeugst du aber ebenso durch Duplicate Content!
Gibt es auf deiner Seite sehr viel Duplicate Content, zieht der Googlebot irgendwann weiter, ohne alle wichtigen URLs unter die Lupe genommen zu haben. Der Googlebot hat kein Interesse daran, Googles Index mit doppelten und dreifachen Informationen zu füllen und seine Zeit mit Websites zu verschwenden, die keinen Mehrwert bieten.
Google ist Duplicate Content nicht egal, so viel ist klar. Wichtig ist ihnen dabei vor allem die User Experience – und die zu verbessern sollte dein erklärtes Ziel sein.
Googles Maßnahmen gegen Duplicate Content
Duplizierte Inhalte gilt es zu vermeiden. So weit, so klar. Trotzdem sieht Google noch lange keinen Grund, sofort Maßnahmen zu ergreifen, außer es liegt ein bewusster Täuschungsfall vor. In diesem Fall behält Google es sich vor, mit aller Härte vorzugehen und die URL aus der Liste der Suchergebnisse zu entfernen. Doch nicht immer erfolgt zwangsläufig eine Abstrafung durch Google.
Aber wie erkennt Google eigentlich Duplicate Content?
Die Suchmaschine crawlt regelmäßig Seiten und identifiziert anhand eines sogenannten Shingle-Algorithmus ähnliche oder identische Textelemente. Dazu wird der Text in Schindeln (daher der Name) unterteilt. Sie bestehen immer aus drei einzelnen Wörtern.
Im Anschluss begibt die Suchmaschine sich sozusagen auf Spurensuche. Anhand wichtiger Faktoren versucht sie herauszufinden, welche Inhalte tatsächlich am relevantesten für die User*innen sind. Dabei werden folgende Elemente berücksichtigt:
- Alter der Inhalte
- Qualität des Contents
- Relevanz des Inhalts
Problematisch wird das Ganze dann, wenn der Algorithmus nicht deine Original-Seite und deinen Original-Inhalt entdeckt, sondern deine Webseite als weniger relevant eingestuft und diese deshalb herausgefiltert wird.
Google Panda und Double Content
Google Panda hat den Ranking-Algorithmus der Suchmaschine auf den Kopf gestellt. Insbesondere Webseiten von zweifelhafter Content-Qualität werden seitdem unnachgiebig abgestraft. Seit Februar 2011 (dem Zeitpunkt des großen Panda-Updates, worauf weitere folgten) dürfen bestimmte Probleme, zu denen eben u. a. Duplicate Content gehört, nicht länger einfach ignoriert werden.
Denn früher betraf Duplicate Content vor allem die entsprechenden Inhalte oder vielleicht die Gesamtanzahl gecrawlter Seiten.
Im post-Panda-Zeitalter jedoch kann doppelter Inhalt dazu führen, dass ein Filter für deine Seite angewandt wird, der die Sichtbarkeit der gesamten Webseite herabstuft. Im Extremfall sorgt er sogar dafür, dass deine Website nicht mehr indexiert wird. Du tust also gut daran, Duplicate Content nicht als isoliertes Problem zu betrachten, sondern im Gesamtkontext zu sehen.
Strafe oder keine Strafe, das ist hier die Frage
Während interner Duplicate Content zwar viele Nachteile (Stichwort: Indexierungsprobleme) mit sich bringt, wird er normalerweise von Google doch nicht in diesem Sinne mit einer Strafe belegt. Schwankungen in den SERPs sind aber wahrscheinlich trotzdem dabei.
Mit externem Duplicate Content – insbesondere, wenn es sich wirklich um bewussten Diebstahl von Content anderer handelt – zieht man wiederum tatsächlich den Unmut der Suchmaschine auf sich und riskiert eine Abstrafung samt nachhaltigen Schäden.
Diese Seiten werden häufig auf die Blacklist verbannt:
- Scraper Sites, also Webseiten, die den größten Teil der Inhalte (oft automatisiert) einfach von anderen kopiert haben
- Content Spinning, d. h. teils automatisiertes Umschreiben von bereits bestehenden Texten, was nichtsdestotrotz eine Urheberrechtsverletzung darstellt
- Doorway Pages: Brückenseiten mit Texten, die einzig und allein für die Suchmaschine geschrieben wurden (mittlerweile fallen für Google auch Local Landing Pages in diese Kategorie)
Urheberschaft erkennen – aber wie?
Best Practice bei Google ist es natürlich, die Seite mit der originalen Urheberschaft zu erkennen. Klar, der Konzern lässt sich hier nur sehr ungern in die Karten blicken. Dennoch ist es wahrscheinlich, dass vor allem darauf geachtet wird, wessen Content als erstes indexiert (und damit vermeintlich geschrieben) wurde.
Ein Problem dahinter: Der Googlebot ist auf Seiten mit mehr externen Links häufiger unterwegs.
Dementsprechend kann es unter Umständen passieren, dass die Fälschung als Original erkannt wird. Du selbst kannst dazu beitragen, dass von dir geteilte Inhalte erst dann weitergegeben werden, wenn deine Seite tatsächlich indexiert wurde. Das kann sich beispielsweise für Preisvergleichsportale als sinnvoll erweisen.
Was tun gegen Duplicate Content?
Ansonsten gilt im Kampf gegen duplizierte Inhalte: Stell sicher, dass deine Webseite regelmäßig auf alle SEO-relevanten Fehler geprüft wird. Dazu gehört auch eine regelmäßige Überprüfung auf Duplicate Content.
Wenn technische SEO und Content Hand in Hand arbeiten, können doppelte Inhalte erfolgreich vermieden werden. Und das ist die wichtigste Strategie, die du gegen doppelte Inhalte fahren kannst.
Wie kann ich doppelten Content vermeiden? (Schnellübersicht)
- Informationsstruktur: Du planst die URL-Struktur deiner Website so, dass Inhalte immer nur unter einer einzigen URL verfügbar sind.
- Canonical Tags: Damit kannst du eine Original-URL bestimmen.
- Meta Robots noindex: So vermeidest du, dass Google die Inhalte indexiert. Nicht empfohlen!
- 301-Weiterleitungen: Du kannst URLs mit doppelten Inhalten auf eine einzige URL weiterleiten.
- Rel=”alternate” / Hreflang Tag: Damit kannst du Google kommunizieren, welche URL für welche Sprachen-Länder-Kombination angezeigt werden soll.
Um dir einen schnellen Überblick zu ermöglichen, wie du Double Content vermeiden kannst, haben wir dir eine kleine Infografik gebastelt.

Duplicate Content Checker: Tools gegen duplizierte Inhalte
Auf dem Markt gibt es einige Tools, die dir dabei helfen können, duplizierte Inhalte aufzuspüren.
Wer sich auf die Suche nach internem Duplicate Content begeben möchte, verwendet Siteliner. So erfährst du, zu wie viel Prozent deine Inhalte tatsächlich einzigartig sind und welche Ähnlichkeiten zu anderen internen Seiten es gibt. 250 Seiten können kostenlos untersucht werden.
Wenn du deine URL eingibst, erhältst du einen super Überblick, wie viele duplizierte Inhalte auf deiner Seite zu finden sind. Sieht ganz gut aus bei uns, oder?
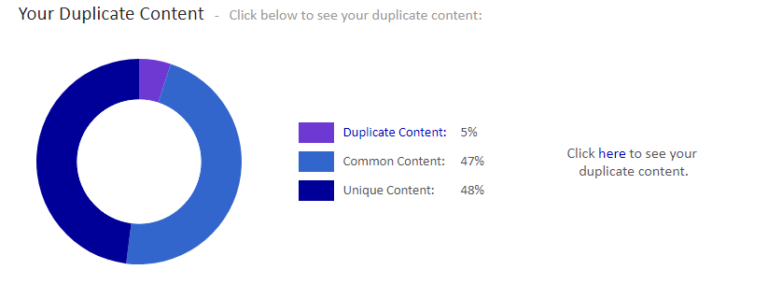
Eine ähnliche Funktion erfüllt Copyscape, wobei so auch externe Quellen verglichen werden können. Wenn du dir nicht sicher bist, ob eine andere Seite einfach von dir abgeschrieben hat, kannst du mit Webconfs zwei Seiten miteinander vergleichen und hast so das Ergebnis schwarz auf weiß.
Google Alerts kann dir – mit den richtigen Voreinstellungen – dabei helfen, externe duplizierte Inhalte zu finden. Wenn du die entsprechenden Textelemente, die du überprüfen lassen möchtest, einträgst (und dabei natürlich deine eigene Seite ausschließt), bekommst du eine Benachrichtigung, wenn der Text erneut im Internet aufgetaucht ist, ohne dass du ihn veröffentlicht hast.
Mit dem richtigen Google-Alerts-Setup wirst du sofort benachrichtigt, wenn jemand deine Inhalte kopiert. Der passende Search Footprint lautet: „Ein spezieller Satz aus deinem Artikel.“ -site:deinewebsite.com
Die tägliche Arbeit eines SEOs
Darüber hinaus kann Duplicate Content am besten vermieden werden, wenn Suchmaschinenoptimierung in Fleisch und Blut übergegangen ist. Aus technischer Sicht bedeutet das, dass du auf eine clevere URL-Struktur und die entsprechenden 301-Weiterleitungen achten solltest.
Content-Syndication bedeutet, Inhalte mehrmals verwenden zu können.
Damit so kein Duplicate Content entsteht, muss im Quellcode semantisch gekennzeichnet sein, woher der Text (das Video, das Bild etc.) ursprünglich stammt. Mit Canonical Tags (rel=“canonical“) kann Google mitgeteilt werden, was die bevorzugte URL ist. Mit noindex-Tags stellst du sicher, dass der Googlebot deine Seite gar nicht erst indexiert. Etwas weiter unten erklären wir dir noch mehr dazu.
Nutze die Einstellungen der Google Search Console voll aus, um duplizierte Inhalte zu vermeiden (Crawling > Parameter) und aus dem Index zu entfernen. Achte vor allem darauf, dass die Suchmaschine keine deiner Platzhalterseiten indexiert. Außerdem solltest du dein Content-Management-System kennen wie kein zweiter. Nur wenn du weißt, wie Content angezeigt wird, weißt du nämlich auch, wo potenzielle Schwierigkeiten lauern.
Anhangsseiten hingegen vermeidest du am besten komplett und leitest alle entsprechenden URLs mit Hilfe eines Plugins direkt auf die entsprechenden Bild-URL weiter. Bei Yoast SEO ist diese Funktion standardmäßig bereits aktiviert.
Strukturen schaffen: Aufräumen gegen Double Content
Im Rahmen der strukturellen OnPage-Optimierung solltest du dafür sorgen, dass alle deine Seiten thematisch absolut eindeutig sind. Jedem Inhalt sollte nur eine URL zugeordnet werden können. Ähnliche Inhalte können auf eine URL zusammengeführt werden. Kreativität (aka Inkonsistenz) bei internen Verlinkungen ist denkbar fehl am Platz, genauso wie unnötige Linkvariationen, die unter einer URL zusammengefasst werden sollten.
Wenn auf deiner Webseite landesspezifischer Content veröffentlicht wird, solltest du Google dabei helfen, zu verstehen, dass es sich hier nicht um Duplicate Content handelt. Dazu verwendest du am besten hreflang Tags (siehe den Punkt Technische SEO für noch mehr Infos), um verschiedene Sprachen bzw. sprachliche Varietäten zu kennzeichnen.
Außerdem benötigst du Domains auf oberster Ebene: mit beispielurl.at gibst du Google schnell und einfach zu verstehen, dass deine Seite Österreich zum Ziel hat.
Technische SEO: Diese Codes musst du dir merken (& richtig anwenden)
Ohne technische Optimierung ist der Kampf gegen Duplicate Content verloren, bevor er begonnen hat. Einige Hinweise auf die technische Seite des Ganzen haben wir bereits erwähnt, aber weil das Thema so wichtig ist und eine Übersicht sicher nicht schadet, möchten wir ihm ein ganzes Unterkapitel widmen.
Wer sich mit den technischen Seiten der Suchmaschinenoptimierung zu wenig auskennt, für den lautet die Devise: Wissen vertiefen (oder natürlich Hilfe von SEO-Experten suchen).
Diese Tags sind die Grundlage, um Duplicate Content zu kennzeichnen und damit ‚unschädlich‘ zu machen.
Meta Robots Tag
Diese Tags enthalten wichtige Informationen über die entsprechende Seite, die für die ‚Augen‘ des Googlebots gedacht sind und entsprechende Anweisungen für den Crawler enthalten. Die Tags sind einigermaßen flexibel, sodass du verschiedene Befehle für Googles intelligentes Helferlein hinterlegen kannst. Das bevorzugte Format im Header sieht dabei aus wie folgt:
[meta name]=“robots“ content=“noindex,follow“
(Achtung: Wir verwenden absichtlich eckige Klammern, statt spitzen Klammern, sonst macht WordPress Faxen)
Was bedeuten die verschiedenen Elemente, die wir am häufigsten verwenden, und warum ist das soeben vorgestellte Format die beste Lösung gegen Duplicate Content, die man sich vorstellen kann?
- noindex: Dieser Tag bedeutet genau das, er sagt also dem Crawler, dass er die Website nicht indexieren soll.
- nofollow: Auch dieser Tag ist einigermaßen selbsterklärend, er sagt dem Googlebot, dass er Links von dieser Seite nicht folgen soll
Auch eine Kombination verschiedener Befehle ist möglich, wie wir bereits gesehen haben. Würde man rein hypothetisch noindex und nofollow setzen, würde das bedeuten, dass die Webseite weder indexiert wird noch Links von der Seite ausgewertet werden.
Update vom 11.02.2019: Google scheint selbst nicht genau zu wissen, wie Meta Robots noindex funktioniert. John Müller und Gary Illyes sind sich jedenfalls so gar nicht einig…
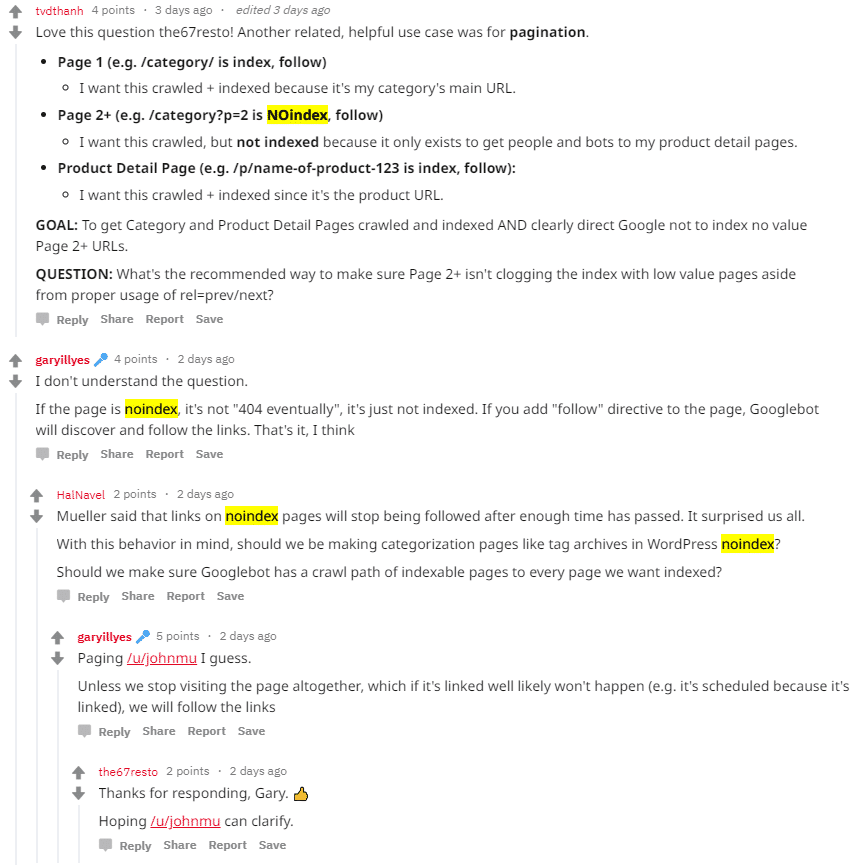
Weitere Informationen zu Robots-Meta-Tags von Google findest du auf dem Developers-Blog.
Canonical Tags
Diese Tags sind ebenfalls HTML-Elemente im Quellcode. Sie helfen dem Googlebot zu unterscheiden, was indexiert werden soll und was nicht. Der Canonical Tag sagt Google, ob es sich um das Original handelt (referenziert sich selbst) oder ob eine andere URL das Original ist.
Wer einen Einblick bekommen möchte, was im Moment indexiert wird, sieht sich die Indexabdeckung in der Google Search Console einmal näher an.
[link rel=“canonical“ href=”https://beispiel.com/unterseite.html”]
(Achtung: Wir verwenden absichtlich eckige Klammern, statt spitzen Klammern, sonst macht WordPress Faxen)
Ein Hinweis dafür, dass ein Fehler in der Indexierung vorliegt, ist eine ungewöhnlich hohe Anzahl an gecrawlten Seiten, viel mehr nämlich, als es auf deiner Seite wirklich gibt. Grund ist häufig eine URL-Struktur, die nicht konsequent genug umgesetzt wurde oder eben fehlende Canonical Tags für Seiten mit ähnlichem oder gleichem Inhalt.
Umso wichtiger ist die Kanonisierung deiner URLs, denn wenn du nicht wählst, wählt der Googlebot für dich. Oder er gibt sogar vorher auf und sieht sich einige deiner wichtigsten Seiten gar nicht weiter an. Was im Moment angezeigt wird, siehst du im URL-Prüftool.
Deine bevorzugte URL gibst du an, indem du den Canonical Tag manuell setzt. Für WordPress ist Yoast SEO dein Freund.
Der Nachteil des rel=“canonical“ ist, dass eine Website dadurch „größer“ werden kann. Auch wenn URLs sich häufig ändern, ist der Tag nicht das richtige Mittel. In diesem Fall sind 301-Redirects sinnvoller. Sie sind nämlich nicht nur für den Googlebot eine Hilfestellung, sondern auch für User, die so den Weg zur neuen URL finden. Gleichzeitig werden Link Juice und Autorität der alten URL übernommen.
Weitere Informationen zum Canonical Tag gibt es natürlich wieder bei Google selbst.
Hreflang
Wir haben es bereits erwähnt: Übersetzungen werden von Google nicht als Duplicate Content bezeichnet und abgestraft. Doch natürlich muss die Suchmaschine irgendwie erkennen, was eigentlich eine Übersetzung bzw. eine Lokalisierung ist. Das Mittel der Wahl dazu heißt hreflang.
Und so sieht es zum Beispiel aus:
[link rel=“alternate“ href=“/beispiel.de/seite.html“ hreflang=“de-AT“ /]
(Achtung: Wir verwenden absichtlich eckige Klammern, statt spitzen Klammern, sonst macht WordPress Faxen)
Mit diesem Attribut teilst du Google mit, in welchen Sprachen eine URL verfügbar ist und welche URL zu welcher Kombination aus Sprache und Land ausgeliefert werden soll. Das ist nicht zuletzt für die User Experience wichtig, so finden User*innen nämlich Inhalte in ihrer Sprache bzw. für ihr Land sofort bei Google und steigen auf der richtigen Version ein.
Googles John Müller hat auf Anfrage übrigens mitgeteilt, dass auch bei identischen Inhalten das hreflang-Attribut dafür sorgt, dass Duplicate Content keine Probleme macht.
Gleichzeitig wird allerdings darauf hingewiesen, dass man mit einzigartigem Content für verschiedene Länder (Stichwort: Lokalisierung!) trotzdem die Nase vorne behalten kann. Denn einzigartige Inhalte kennen keine Ländergrenzen! Am besten überlegst du dir auch, ob deine User*innen in einem anderen Land vielleicht etwas anderes sehen und lesen wollen.
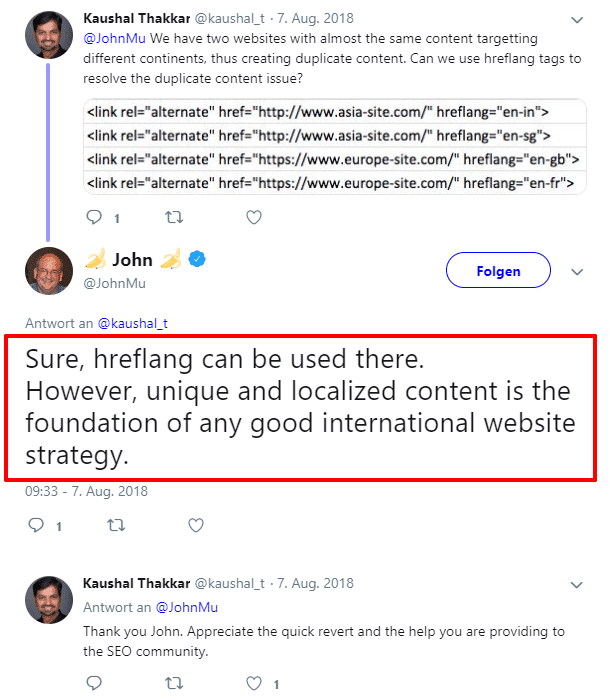
Weitere Informationen zum Hreflang Tag von Google gibt’s beim Google-Support.
Google Search Console und die bevorzugte Domain
In der Google Search Console kannst du deine bevorzugte Domain festlegen (www vs. ohne www; https vs. http). Wichtig ist das, da Google sonst diese zwei unterschiedlichen Formate unter Umständen als unterschiedliche Seiten ansieht.
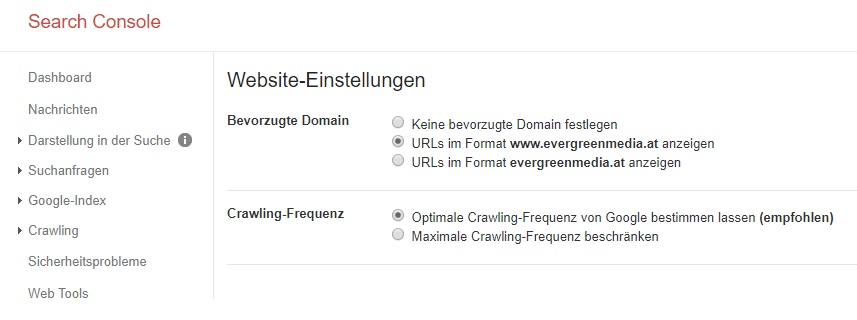
Auch Parameter kannst du in der Google Search Console kategorisieren. So wird deutlich, welchem Zweck sie dienen sollen und weshalb es sich bei ihnen nicht um Duplicate Content handelt. Ein Beispiel, das Google selbst anführt, sind Online Shops. Hier dient beispielsweise der Parameter „country“ als Verweis für das Geotargeting. Es zeigt, dass unterschiedliche Seiten für verschiedene Länder vorgesehen sind.
Aber Achtung:
Einstellungen an den Parametern sollten nur dann vorgenommen werden, wenn man gewisse Vorkenntnisse mitbringt und sichergestellt ist, dass Seiten nicht versehentlich vollkommen aus dem Sichtfeld verschwinden.
Unique statt Duplicate: So schaffst du einzigartige Inhalte
Manchmal scheint es, als würden wir es fast gebetsmühlenartig wiederholen und trotzdem an dieser Stelle noch einmal: Guter, einzigartiger Content ist die beste Medizin gegen doppelte Inhalte. Und die Schritte dorthin sind nicht schwierig.
Alles, was zu diesem Zeitpunkt noch nach zu ähnlichem Content aussieht, sollte soweit wie irgend möglich minimiert und eliminiert werden.
Auch wiederkehrende Textbausteine gilt es laut Google selbst möglichst zu vermeiden. Entweder du fasst dich in Sachen Disclaimer am Ende beispielsweise sehr kurz oder aber verlinkst die ausführlichen Zusammenfassungen.
Darüber hinaus lautet das Credo in Sachen Content so richtig kreativ zu werden und das eigene Expertenwissen in der großen, weiten Welt des Internets zu verbreiten.
Ganz wichtig dabei: Eigenen Content produzieren, der die Suchintention im Kern trifft. Nur zu 80 oder 90 Prozent einzigartig zu sein, reicht nicht aus, um ein Top-Ranking zu erzielen. Unser bester Tipp für Unique Content lautet übrigens, den Blickwinkel der User*innen einzunehmen und so zu schreiben, dass sie sich zu 100 Prozent verstanden fühlen.
Du willst genau wissen, was du an deiner Website ändern musst, um bei Google besser zu ranken?
Was du gegen Content-Diebstahl machen kannst
Und dann kommt vielleicht doch der düstere Tag, an dem ein Google Alert dich darauf aufmerksam macht, dass deine einzigartigen Inhalte an einer anderen Stelle im Internet aufgetaucht sind. Und das ohne dein Wissen. Aber was sollst du jetzt tun?
Das ist wohl abhängig von der Situation selbst. Diese Möglichkeiten hast du:
Abwarten und Tee trinken
Wenn Google dem Content-Diebstahl bereits auf der Spur ist und noch dazu die andere Seite ein deutlich schlechteres Domain-Rating hat als deine eigene Webseite, musst du dir nicht allzu große Sorgen machen. Zumindest einen Spamreport wegen einer Verletzung des Urheberrechts solltest du aber trotzdem ausfüllen.
Mit dem Webmaster Kontakt aufnehmen
Oder aber du wendest dich an den/die Besitzer*in (oder zumindest Betreuer*in) der Webseite. Nenne die konkreten Passagen, um die es geht, und weise freundlich, aber bestimmt auf die Urheberrechtsverletzungen hin.
Ohne eine konkrete Frist zur Entfernung wirst du wahrscheinlich alt und grau werden, ehe dein Content von der anderen Seite verschwindet. Lieber selbst einen Zeitraum angeben.
Weitere rechtliche Schritte setzen
Es ist die Ultima Ratio, doch wenn der bzw. die Webseitenbesitzer*in sich absolut uneinsichtig zeigt, bleibt dir noch immer der Weg, einen juristische Fachleute einzuschalten. Wie gesagt, das ist für alle Beteiligten sehr ungemütlich und sollte deshalb nicht das erste Mittel der Wahl sein. Gleichzeitig ist aber auch klar, dass das Internet eben kein rechtsfreier Raum ist.
Damit dein Content gar nicht erst gestohlen werden kann oder du etwas gegen vermeintliche Inhalts-Diebe in der Hand hast, kannst du übrigens einige Maßnahmen ergreifen:
Kopierschutz einrichten
So machst du deine Seite unkopierbar, sodass andere viel weniger leicht ‚abschreiben‘ können. Unmöglich ist es allerdings trotzdem nicht und auch die Nutzererfahrung leidet deutlich. Wir alle wissen von uns selbst, wie häufig wir einfach schnell mal einen Inhalt in die Zwischenablage speichern, um ihn jemandem weiterzuleiten oder später wieder zu finden.
Hinweis auf Urheberrecht und Copyright
Mit einem solchen Vermerk sind zumindest die rechtlichen Konsequenzen für alle Besucher*innen deiner Seite klar und deutlich zu erkennen. Im Idealfall wirkt ein prominent platzierter Hinweis abschreckend. Natürlich kann Scraping so nicht verhindert werden, aber zumindest ist dann von vornherein klar: Du verstehst keinen Spaß, wenn es um die unerlaubte Verwendung deines Contents geht.
Keine Panik auf der Titanic. Wenn andere deine Inhalte geklaut haben, sind dir nicht die Hände gebunden.
Wer weiß, manchmal motiviert es dich vielleicht sogar dazu, noch bessere und noch aktuellere Inhalte zu veröffentlichen!
SEO-Fehler, die du bei Duplicate Content vermeiden solltest
Wir wissen es selbst: Eigentlich ist es nicht sinnvoll, am Ende eines Ratgebers alles aufzuzählen, was man so falsch machen kann. Schließlich bleibt im Kopf, was am Ende gesagt wird.
Da es aber gleichzeitig eine gute Zusammenfassung ist, wagen wir es trotzdem – und hoffen, du setzt unsere praktischen Tipps gerne und erfolgreich um:
Nicht dem Crawler den Zugriff verwehren
Auf keinen Fall solltest du Duplicate Content in der robots.txt so kennzeichnen, dass deine Seite nicht mehr gecrawlt wird. Das ist eine nicht sehr elegante Variante, die sich mit rel=“canonical“ oder noindex um einiges besser lösen lässt.
Nicht einfach URLs mit Double Content löschen
Wenn URLs mit Duplicate Content ein Problem sind, weshalb dann nicht einfach die entsprechenden URLs löschen? Die URLs können gelöscht werden, müssen aber vorab auf das Original weitergeleitet werden. Alternativ kannst du sie bestehen lassen und mit dem Canonical Tag das Original bestimmen.
Häufig ist die Ursache für doppelte Inhalte aber eine schlechte URL-Struktur. Nimm dir die Zeit, eine bessere Informationsstruktur auszuarbeiten. Es lohnt sich!
Nicht mit fremden Federn und Wörtern schmücken
Dein Content sollte zu 100 % einzigartig und authentisch sein. Gute Inhalte, die liebevoll aufbereitet sind und für die Besucher*innen deiner Seite einen echten Mehrwert bieten, sind ein echtes Qualitätsmerkmal.
Duplicate Content unter Kontrolle zu bekommen, ist im Grunde kein Kunststück. Möglich wird es, indem du immer wieder kontrollierst, was bereits auf deiner Webseite passiert ist, sorgfältig arbeitest und technisch immer auf dem neusten Stand bleibst.
Häufig gestellte Fragen zu Duplicate Content
Doppelter Inhalt führt nicht unbedingt dazu, dass eine Website abgestraft wird. Der Google Algorithmus entscheidet sich lediglich für eine Version als Original. Doppelte Inhalte sind also nicht in jedem Fall ein Grund zum Handeln, es sei denn, man will mit jeweiligen Seite in den Suchergebnissen aufscheinen. Dann müssen die Inhalte auf dieser Seite einzigartig sein.
Trotzdem kann es bei großen Mengen an Duplicate Content auf einer Website zu einem Rückgang des Crawl-Budgets kommen. Alternativ kann eine Website mit dünnen oder doppelten Inhalten auch in den Google-Panda-Filter geraten.
Der Canonical Tag teilt Suchmaschinen mit, dass eine bestimmte Seite so behandelt werden sollte, als wäre sie eine Kopie einer anderen URL, und alle Link- und Relevanzmetriken sollten der im Canonical Tag angegebenen URL zugeordnet werden.
Meta Robots noindex, follow ermöglicht es Suchmaschinen, die Links auf einer Seite zu durchsuchen, hält sie aber davon ab, die Seite in ihre Indizes aufzunehmen. Es ist wichtig, dass die duplikate Seite immer noch gecrawlt werden kann, auch wenn wir Google sagen, sie nicht zu indizieren. Google wart ausdrücklich davor, den Crawlerzugriff auf doppelte Inhalte auf einer Website einzuschränken.
Wenn viele verschiedene Online-Shops die gleichen Artikel verkaufen und sie alle die Artikelbeschreibungen des Herstellers verwenden, werden identische Inhalte an mehreren Stellen im Internet bereitgestellt. Doppelte Produktbeschreibungen stellen ein Problem für Online-Shops dar, weil Suchmaschinen sich weigern, diese URLS zu indexieren und ranken. Bei großen Mengen an Produktseiten mit duplikaten Inhalten kann eine Shop-Website in den Google-Panda-Filter geraten oder das Crawl-Budget drastisch reduziert werden.
Am schnellsten findet man Cross-Domain Duplicate Content mit dem Tool CopyScape. Das Werkzeug hilft dabei herauszufinden, ob Artikel auf der eigenen Website kopiert wurden, aber auch ob andere Websites deine Inhalte stehlen. Copyscape bietet die weltweit leistungsfähigsten Lösungen zur Erkennung von Plagiaten im Internet.
In manchen Fällen ist Cross-Domain Duplicate Content ganz normal. Nehmen wir an, ein Gastartikel von dir wurde bei einem bekannten Online-Magazin veröffentlicht und du willst den Artikel unbedingt auch auf deiner eigenen Website publizieren. Um die Situation SEO-freundlich zu lösen, würdest du von dem Gastartikel auf deiner Website einen Canonical Tag auf den Gastartikel beim Online-Magazin setzen. Natürlich ist dieser Schritt nicht sinnvoll, wenn das Ziel des Gastartikels ein SEO-relevanter Backlink ist.
✓ über 25.000 Abonnenten ✓ min. ein neues Video pro Woche ✓ geballtes Praxiswissen





Wie immer ein guter Beitrag. Hab nur nochmal eine Frage zum AMP.
Nun habe ich eine Webseite und ein aktiviertes AMP Plugin.
Jetzt reiche ich meine Webseite bei Google über die Webmastertools ein und auch die AMP Version ist das dann auch DC?
Obwohl die WordPress AMP Pluigins einen Canonical tag hinterlegen?
Falls wir schon dabei sind müssen überhaupt beide Versionen eingereicht werden?
Vielen Dank im Vorraus.
Hallo Aktiennovice,
der Canonical Tag ist dazu da, um ein Original zu bestimmen, also handelt es sich nicht um Duplicate Content. Reiche einfach deine normale Sitemap ein und der Rest geht von selbst 😉
Viele Grüße aus Innsbruck,
Alexander
Vielen Dank, Alexander!
Habt ihr vielleicht eine gute Empfehlung was Duplicate Content auf Plattformen wie Ebay und Amazon zum Shop betrifft?
Hallo Alexander,
hmmmm, ich schätze, du meinst, dass du dort die gleichen Inhalte wie auf deiner Website verwenden willst. Das solltest du nicht machen 😉
Viele Grüße,
Alexander
Hallo Alex,
vielen Dank für den ausführlichen Artikel.
Sag mal, wie macht man das für Seiten, die oft Pressemitteilungen oder News veröffentlichen, die auch auf anderen Portalen veröffentlicht wurden?
Reicht es aus, das Original zu verlinken oder wie geht man dabei vor?
Danke dir!
Dominik
Hallo Dominik,
die Frage ist, wieso du das machen willst, wenn du dich auch mit SEO beschäftigst? Denn diese Inhalte können dann nicht bei Google ranken, weil es Duplikate sind.
Am besten zeigst du von der jeweiligen Seite auf deiner Website mit dem Canonical Tag auf das Original.
Viele Grüße,
Alexander
Danke für die Antwort, Alexander.
Habe gefragt, da ich einen Kunden habe, der in diesem Bereich aktiv ist.
Alles klar, dann werde ich das so machen. 🙂
Liebe Grüße
Dominik
Hallo Alex,
vielen Dank für Deine ausführlichen Artikel und Videos, diese helfen echt weiter. Ich habe allerdings zu dem Thema in diesem Artikel folgende Frage:
Auf meiner Website sind die Produktseiten auf NOINDEX, FOLLOW gesetzt. Hätte es für das Ranking eine Auswirkung, wenn ich auf den einzelnen Produktseiten INDEX, FOLLOW einstellen würde, dabei aber ein Canonical auf die jeweilige Kategorieseite?
VIELEN DANK und viele Grüße
Klaus
Hallo Klaus,
vielen Dank für deinen Kommentar!
Wieso sind deine Produktseiten auf noindex,follow? Bez. Canonical von Produktseiten auf Kategorieseiten. Das bezeichnen wir als den Canonical-Hack und dieser funktioniert seit geraumer Zeit nicht mehr bzw. stellt ein Risiko dar.
Viele Grüße aus Innsbruck,
Alexander
Reicht wenn man bei intern Duplicate auf Noindex + Weiterleitung macht? Oder reicht eine 301 Weiterleitung vollkommen?